Building Search Engines with Gensim¶

- PhD candidate @ University of Alabama
- Roll tide 🌀🌊🌀🐘🏈💯
- Search applications for software maintenance tasks
- Code search
- Change request triage
- Currently visiting researcher @ ABB
- Looking for new adventures in 2016!
- I have a Twitter ✌️problem✌️
- I tweet really dumb things sometimes
- I am looking for a job
I was apparently spotted on the local news being a drunk Alabama fan that flooded the streets after the win last night. Whoops.
— christop corley (@excsc) January 10, 2012instead of lunch I am just going to have a bunch of beers and eat pretzels
— christop corley (@excsc) September 29, 2014*CLARIFICATION: I do not "have a drinking problem", as my mother likes to claim. I am probably actually quite sober right now!
Let's make a search engine¶
search("drunk") => [tweets containing the word 'drunk']
search("drunk") => [tweets *related* to the word 'drunk']
import gensim
I'm a gensim contributor
gensim's ✌️design✌️ is not always great, certainly better tools exist that can supplement or replace parts of this talk, e.g.:
whooshnltkscikit-learn
grep is great, but¶
- must search through all documents
- not aware of language-specific semantics
- does not rank by relevence
Basics¶
- Prepare the corpus
- Model the corpus
- Index the corpus
- Query fun-time!
cat_phrases = ["meow",
"meow meow meow hiss",
"meow hiss hiss",
"hiss"
]
cat_lang = ["meow", "hiss"]
cat_phrase_vectors = [[1, 0],
[3, 1],
[1, 2],
[0, 1]]
plot_vecs(cat_phrase_vectors, labels=cat_lang)

cat_lang = ["meow", "hiss"]
cat_phrase_vectors = [[1, 0],
[3, 1],
[1, 2],
[0, 1]]
other_cat = [1, 1]
plot_vecs(cat_phrase_vectors, other_cat, labels=cat_lang)

for cat in cat_phrase_vectors:
print("%s => %.3f" % (cat, 1 - scipy.spatial.distance.cosine(cat, other_cat)))
cat_lang3 = ["meow", "hiss", "purr"]
cat_phrase_vectors3 = [[1, 0, 3],
[3, 1, 1],
[1, 2, 0],
[0, 1, 3]]
other_cat3 = [1, 1, 2]
plot_vecs(cat_phrase_vectors3, other_cat3, labels=cat_lang3) # matplotlib whyyy

Preparing the corpus¶
- Tokenizing
text = "Jupyter/IPython notebook export to a reveal.js slideshow is pretty cool!"
text.split()
list(gensim.utils.tokenize(text))
When do we want to tokenize?¶
list(gensim.utils.tokenize("Jupyter/IPython"))
list(gensim.utils.tokenize("AC/DC"))
Preparing the corpus¶
- Tokenizing
- Normalizing
text.lower()
"ipython" => "ipython""IPython" => "ipython""iPython" => "ipython"
When do we want to normalize?¶
"TriPython".lower()
"Apple".lower()
Preparing the corpus¶
- Tokenizing
- Normalizing
- Stopword removal
' '.join(sorted(gensim.parsing.STOPWORDS))
list(gensim.utils.tokenize(text.lower()))
[word for word in gensim.utils.tokenize(text.lower()) if word not in gensim.parsing.STOPWORDS]
import nltk
nltk.download('stopwords')
' '.join(sorted(nltk.corpus.stopwords.words('english')))
When do we want to remove stop words?¶
[word for word in "the cat sat on the keyboard".split() if word not in gensim.parsing.STOPWORDS]
[word for word in "the beatles were overrated".split() if word not in gensim.parsing.STOPWORDS]
Preparing the corpus¶
- Tokenizing
- Normalizing
- Stopword removal
- Short/Long word removal
- Words that appear in too many or few documents
[word for word in "the cat sat on the keyboard lllllbbbnnnnnbbbbbbbbbbbbbbbbb".split()
if len(word) > 2 and len(word) < 30]
Preparing the corpus¶
- Tokenizing
- Normalizing
- Stopword removal
- Stemming
for word in "the runner ran on the running trail for their runs".split():
stemmed_word = gensim.parsing.stem(word)
if stemmed_word != word:
print(word, "=>", stemmed_word)
When do we want to stem words?¶
gensim.parsing.stem("running")
gensim.parsing.stem("jupyter")
Stemming alternative: lemmatization!¶
gensim.utils.lemmatize("the runner ran on the running trail for their runs",
allowed_tags=re.compile(".*"))
gensim.utils.lemmatize("the runner ran on the running trail for their runs")
Putting it all together¶
def preprocess(text):
for word in gensim.utils.tokenize(text.lower()):
if word not in gensim.parsing.STOPWORDS and len(word) > 1:
yield word
list(preprocess("Jupyter/IPython notebook export to a reveal.js slideshow is pretty cool!"))
gensim.parsing.preprocess_string("Jupyter/IPython notebook export to a reveal.js slideshow is pretty cool!")
The corpus¶
My twitter archive
!head -1 tweets.csv
import csv
class TwitterArchiveCorpus():
def __init__(self, archive_path):
self.path = archive_path
def iter_texts(self):
with open(self.path) as f:
for row in csv.DictReader(f):
if (row["retweeted_status_id"] == "" and # filter retweets
not row["text"].startswith("RT @") and
row["in_reply_to_status_id"] == "" and # filter replies
not row["text"].startswith("@")):
yield preprocess(row["text"])
tweets = TwitterArchiveCorpus("tweets.csv")
texts = tweets.iter_texts()
print(list(next(texts)))
print(list(next(texts)))
!head -3 tweets.csv | awk -F '","' '{print $6}'
Basics¶
- Prepare the corpus
- Model the corpus
- Index the corpus
- Query fun-time!
plot_vecs(cat_phrase_vectors, other_cat, labels=cat_lang)
class TwitterArchiveCorpus():
def __init__(self, archive_path):
self.path = archive_path
self.dictionary = gensim.corpora.Dictionary(self.iter_texts())
def iter_texts(self):
with open(self.path) as f:
for row in csv.DictReader(f):
if (row["retweeted_status_id"] == "" and # filter retweets
not row["text"].startswith("RT @") and
row["in_reply_to_status_id"] == "" and # filter replies
not row["text"].startswith("@")):
yield preprocess(row["text"])
def __iter__(self):
for document in self.iter_texts():
yield self.dictionary.doc2bow(document)
def __len__(self):
return self.dictionary.num_docs
def get_original(self, key):
pass # let's not look at this :-)
tweets = TwitterArchiveCorpus("tweets.csv")
{"meow": 0,
"hiss": 1,
"purr": 2}
vecs = iter(tweets)
print(next(vecs))
print(next(vecs))
texts = tweets.iter_texts()
print(list(next(texts)))
print(list(next(texts)))
print(tweets.get_original(0))
print(tweets.get_original(1))
len(tweets), len(tweets.dictionary)
(len(tweets) * len(tweets.dictionary)) / (1024 ** 2)
Basics¶
- Prepare the corpus
- Model the corpus
- Index the corpus
- Query fun-time!
plot_vecs(cat_phrase_vectors, other_cat, labels=cat_lang)
index = gensim.similarities.Similarity('/tmp/tweets',
tweets,
num_features=len(tweets.dictionary),
num_best=15)
!ls /tmp/tweets*
Basics¶
- Prepare the corpus
- Model the corpus
- Index the corpus
- Query fun-time!
plot_vecs(cat_phrase_vectors, other_cat, labels=cat_lang)
query_bow = tweets.dictionary.doc2bow(preprocess("drunk"))
query_bow
index[query_bow]
def search(query):
query_bow = tweets.dictionary.doc2bow(preprocess(query))
for doc, percent in index[query_bow]:
print("%.3f" % percent, "=>", tweets.get_original(doc), "\n")
search("drunk")
search("bar")
A more slightly more advanced model¶
lsi = gensim.models.LsiModel(tweets,
num_topics=100,
power_iters=10,
id2word=tweets.dictionary)
len(tweets), len(tweets.dictionary)
len(tweets), lsi.num_topics
lsi_index = gensim.similarities.Similarity('/tmp/lsitweets',
lsi[tweets],
num_features=lsi.num_topics,
num_best=15)
def lsi_search(query):
query_bow = tweets.dictionary.doc2bow(preprocess(query))
for doc, percent in lsi_index[lsi[query_bow]]:
print("%.3f" % percent, "=>", tweets.get_original(doc), "\n")
search("pigpen") # non-LSI search
lsi_search("pigpen")
WE NEED TO GO DEEPER BRRRRRRRAAAAAWWWWRWRRRMRMRMMMMM¶

A deep-learning approach¶
Warning: here be Gensim dragons
gif credit: http://prostheticknowledge.tumblr.com/post/128044261341/implementation-of-a-neural-algorithm-of-artistic
w2v = gensim.models.Word2Vec.load_word2vec_format('GoogleNews-vectors-negative300.bin.gz',
binary=True)
How does "king - man + woman = queen"?¶
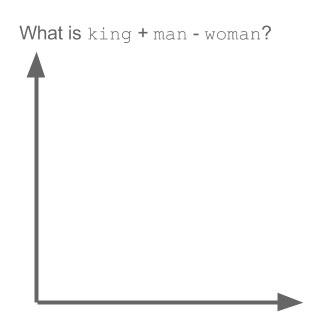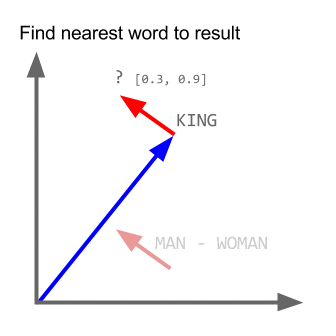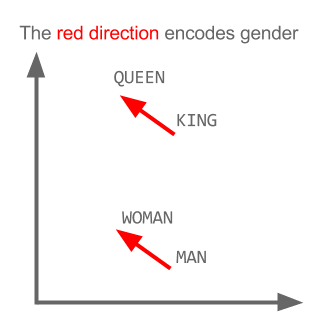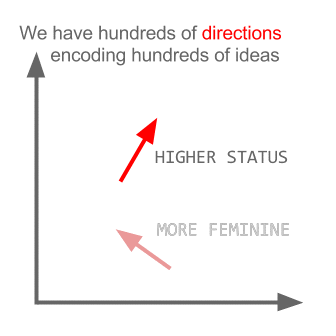
gif credit: http://multithreaded.stitchfix.com/blog/2015/03/11/word-is-worth-a-thousand-vectors/
def generate_vector_sums():
for doc in tweets.iter_texts(): # remember me?
yield gensim.matutils.unitvec( # DRAGON: hack to make Similarity happy with fullvecs
sum(
(w2v[word] for word in doc if word in w2v),
numpy.zeros(w2v.vector_size)
)
)
w2v_index = gensim.similarities.Similarity('/tmp/w2v_tweets',
generate_vector_sums(),
num_features=w2v.vector_size,
num_best=15)
def search_w2v(query):
query_tokens = preprocess(query)
query_vec = gensim.matutils.unitvec(sum((w2v[word] for word in query_tokens if word in w2v), numpy.zeros(w2v.vector_size)))
for doc, percent in w2v_index[query_vec]:
print("%.3f" % percent, "=>", tweets.get_original(doc), "\n")
search_w2v("drunk")
search_w2v("kittens")
Thanks for listening! 😻🍻😸¶
(Is it beer-time yet?)
plot_vecs(cat_phrase_vectors, other_cat, labels=["meow", "hiss"])
No tweets were harmed as a result of this talk.
I am a person; people make mistakes and that's okay.
Short-circuiting a full search: inverted index!¶
cat_lang3 = ["meow", "hiss", "purr"]
cat_phrase_vectors3 = [[1, 0, 3],
[3, 1, 1],
[1, 2, 0],
[0, 1, 3]]
inv_index = defaultdict(set)
for doc_id, doc in enumerate(cat_phrase_vectors3):
for word_id, freq in enumerate(doc):
if freq:
inv_index[word_id].add(doc_id)
inv_index[0]
inv_index[0].intersection(inv_index[1])